
網站分析工具Screaming Frog是SEO必備工具,可以爬取、分析網站的技術面問題與上稿狀況,讓SEO人員快速地掌握網站問題、擬定修正方向。但實務上,其實蠻容易遇到無法以Screaming Frog爬取的網站,這篇文章便是分享我遇過的問題並提出建議方式。文章目錄:
在進入本文之前先提醒幾件事:
- 這邊對應的版本是付費版,免費版只能爬取500個網址、功能也有所限制,可能無法調整這邊介紹的設定
- 以下的問題通常也會造成SEO問題、需要處理掉,單單讓Screaming Frog繞過這些障礙來爬取網站是不夠的
- 如果不熟悉它的基本操作,請參考Screaming Frog基礎教學,本文算是進階篇、不會說明基礎使用方式
連結格式問題
想要理解何謂連結格式問題就要先了解Screaming Frog的運作邏輯。通常我們是以「Spider」模式來爬取網頁,也就是輸入一個網址之後,Screaming Frog會找尋這個網址上「合規」的內部連結開始爬取網站內容,這邏輯跟Google爬蟲的運作邏輯是一致的。為何我特別強調「合規」呢?
根據Google的說法,它的爬蟲只認得a href=””這種格式的網址,這是正規的網址元素格式。若網址有違Google可接受的格式就很容易造成Google爬蟲爬取網站的障礙,而Screaming Frog遇到不符合這個格式的網址,通常也無法爬取。
若遇到這種網站Screaming Frog會瞬間結束,可能網站有上百個頁面,但它只會爬了10來個頁面就顯示已完成。
檢查的方式很簡單,爬取前先到想爬取的頁面(就是輸入Screaming Frog的那個頁面)看一下那頁面上的內部連結格式。正常來說,鼠標滑到連結時,瀏覽器左下方應該要顯示該連結的網址才對,如無顯示就要使用瀏覽器的開發者工具確認連結格式。不理解的話請看下圖說明,先提供正規格式,再提供有問題的格式。
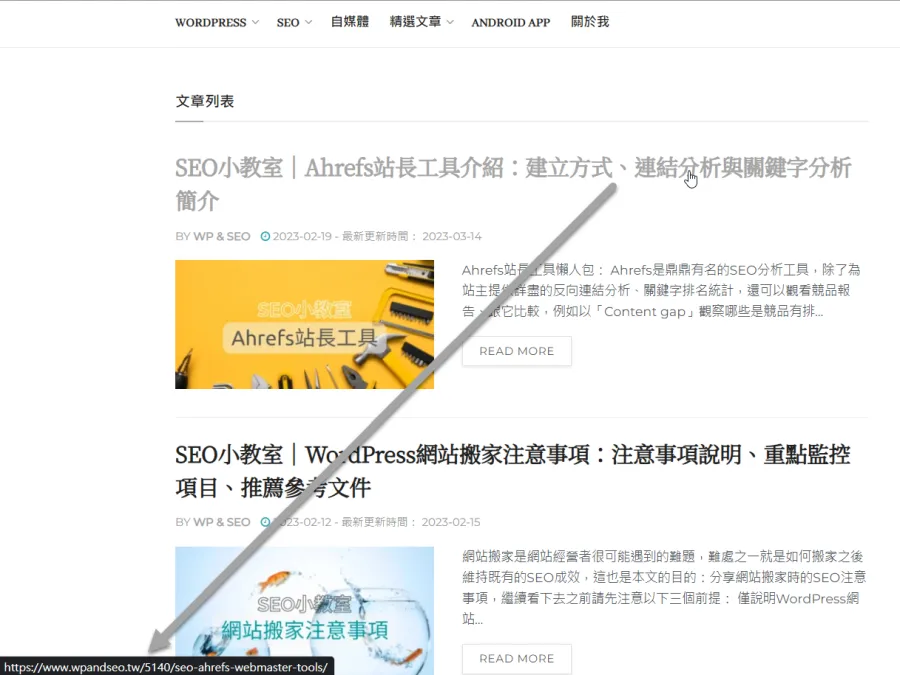
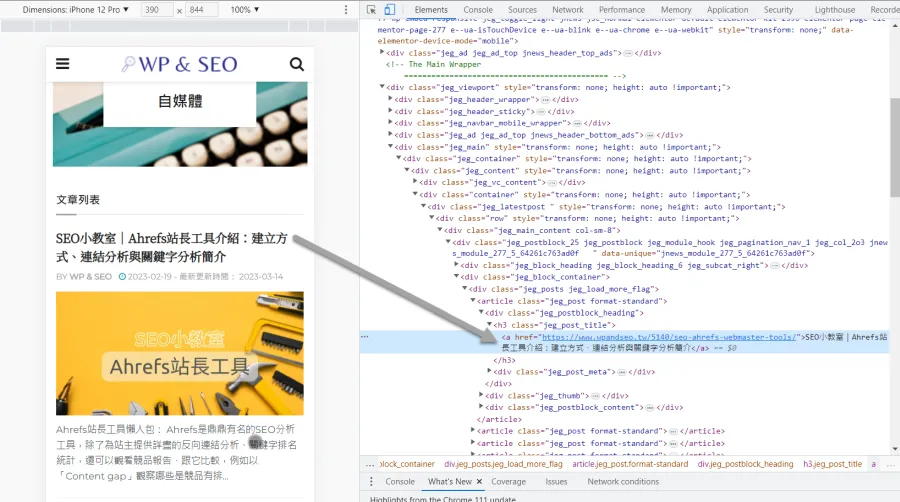

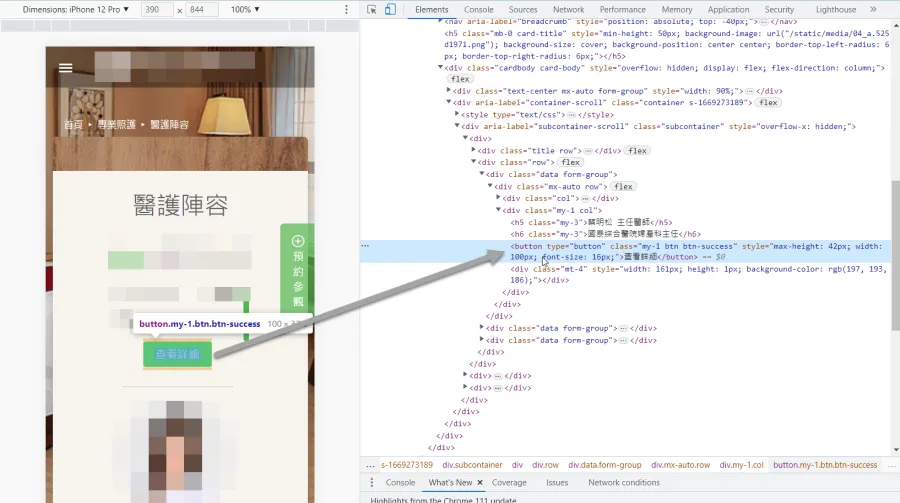

遇到這個問題該怎樣解決呢?只能先以「List」模式列出想要Screaming Frog爬取的網址。這是非常嚴重的SEO問題,代表了Google的爬蟲無法爬取網站內部連結來了解網站內容以及頁面間的關聯,是SEO大忌。
User-Agent問題
User-Agent的中文翻譯是使用者代理程式,以網站運作來說,它的用途就是用來跟網站主機表明是哪個程式來請求檢視網站內容(Google的說明),Screaming Frog也有自己的User-Agent。有的主機會拒絕特定User-Agent檢視網站內容,如果該主機拒絕Screaming Frog的User-Agent來檢視網站,自然就會造成Screaming Frog無法爬取網站。
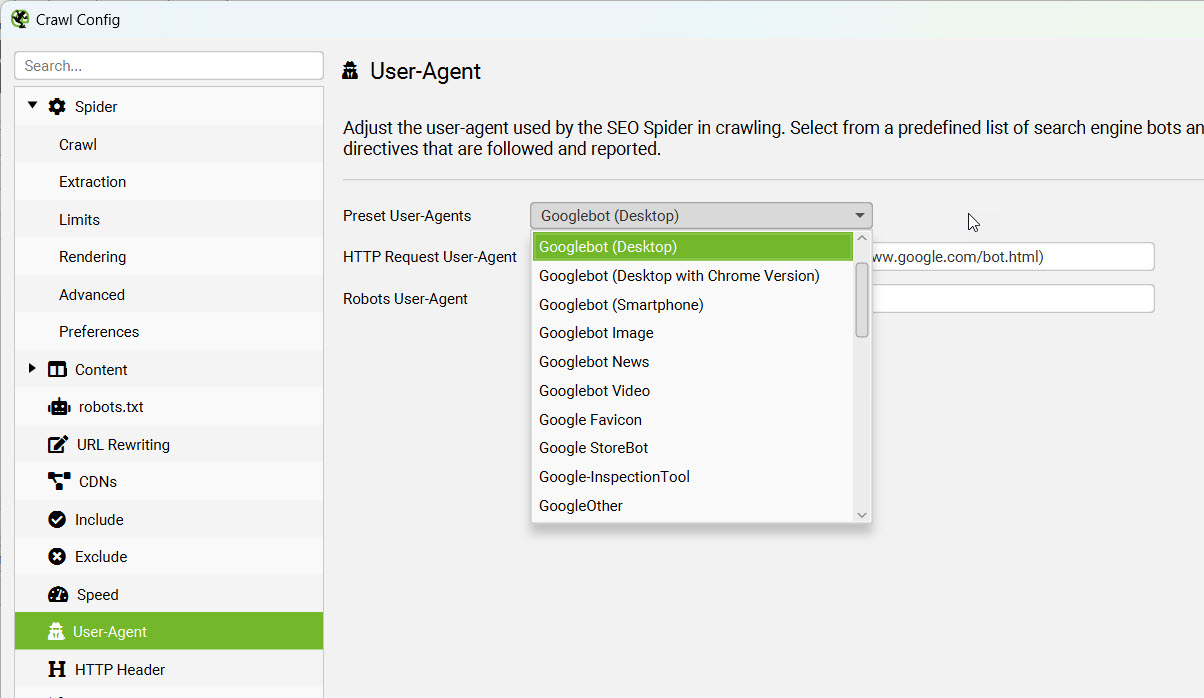
這問題的解決方式很簡單,變更Screaming Frog的User-Agent即可,路徑:「Configuration」-「User-Agent」,將User-Agent變更為Google的爬蟲即可。如果已經完成變更還是無法順利爬取,那就代表有其他問題、需要再深究其他原因。
Robots.txt封鎖問題
Robots.txt是個文字檔案格式的網頁(Google說明文件),其中一個用途是用來說明這個網站哪些內容不能被哪一種User-Agent爬取。
通常…這不會是造成Screaming Frog不能爬取網站的原因,但我還真的有遇過這個檔案設定有問題造成的爬取問題,例如:網站需要先執行JavaScript才可以產生內容,然後又封鎖爬蟲爬取所需的JavaScript檔案。這時候即使要Screaming Frog先執行JavaScript也沒用,因為網站的robots.txt禁止它爬取這些檔案。
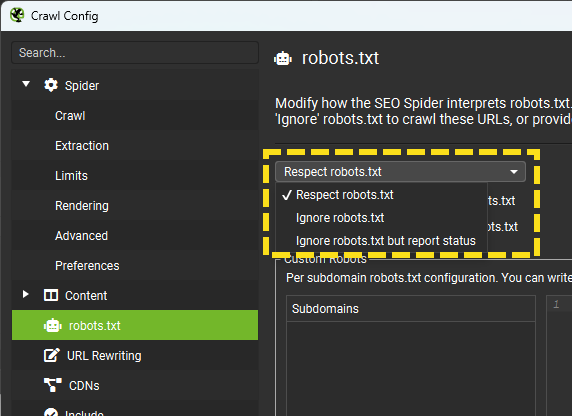
要判定是否有因為robots.txt造成爬取問題很簡單,只要檢視它的設定即可,路徑統一是:網域/robots.txt,每個網站都一樣,例如本站是:https://www.wpandseo.tw/robots.txt。如果發現因為這個檔案造成爬取問題,可於「Configuration」-「robots.txt」-「Settings」調整為「Ignore robots.txt」。
這個調整只是用來處理robots.txt造成的Screaming Frog爬取問題,無法處理錯誤設定造成的SEO問題,錯誤的robots.txt設定會大大的傷害SEO,一定要修正、不能置之不理。
JavaScript相關問題
為何JavaScript會造成Screaming Frog的爬取問題呢?如果網站依賴執行JavaScript來顯示內容,因為Screaming Frog的預設值是不執行JavaScript,自然看不到重要的網站內容、無法爬取。這種依賴在瀏覽器端執行JavaScript來顯示內容的運作方式稱為"Client-side rendering (CSR)",是蠻容易造成SEO問題的(Google的說明)。
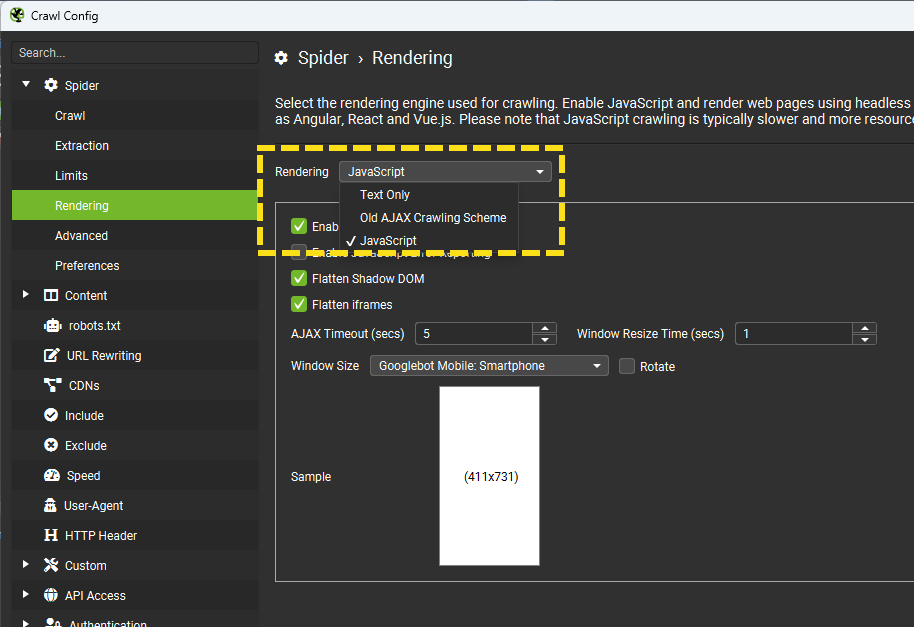
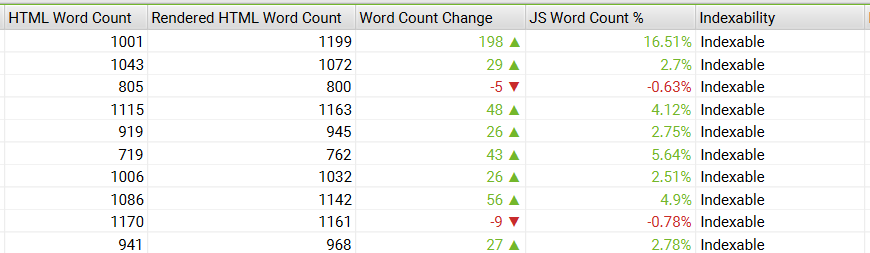
要如何判斷是否因為JavaScript造成Screaming Frog無法爬取呢?很簡單,要求Screaming Frog在爬取時先執行JavaScript來渲染網頁內容,設定路徑:「Configuration」-「Spider」,切換到「Rendering」後選擇「JavaScript」,開啟之後會需要花更多的時間爬取。
完成後切換到頁籤「JavaScript」之後再選擇「Contains JavScript Content」並觀察「JS Word Conut %」的數據,這是代表有多少百分比的文字內容是需要先執行JavaScript才能顯示。
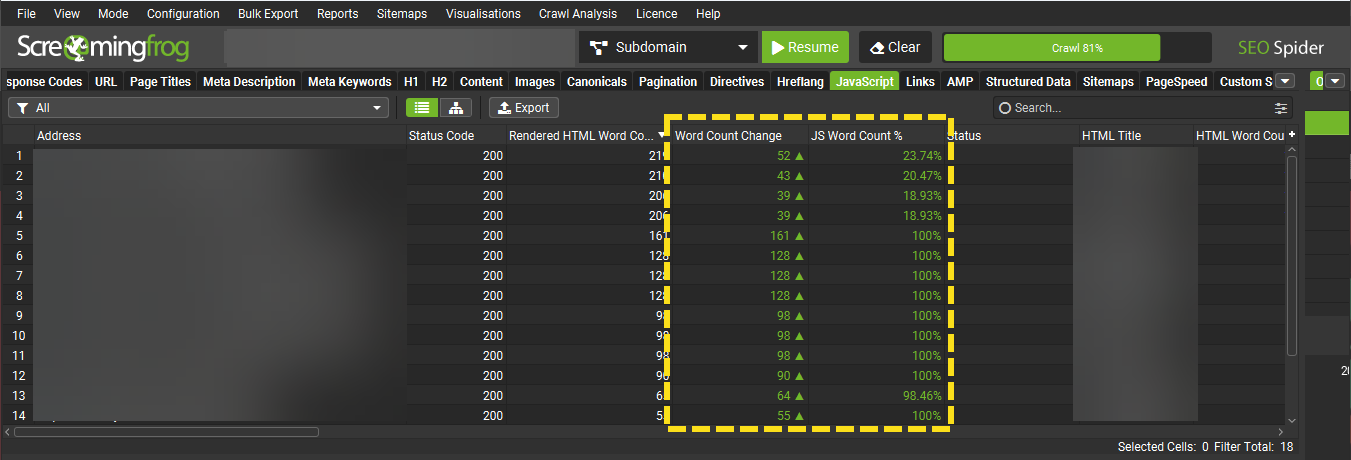
要注意的是….這邊要給一個容錯值,網站多多少少都會有內容需要先執行JavaScript才能顯示,例如推薦文章、推薦商品、YT影片嵌入等等,如果上述資料大多落在10%以內是不用太擔心,強要這邊修正為0是矯枉過正。如果用預設的渲染方式-Text Only就能看到大多數的網站內容,是不用擔心有JavaScript產生的SEO問題。
主機端防火牆問題
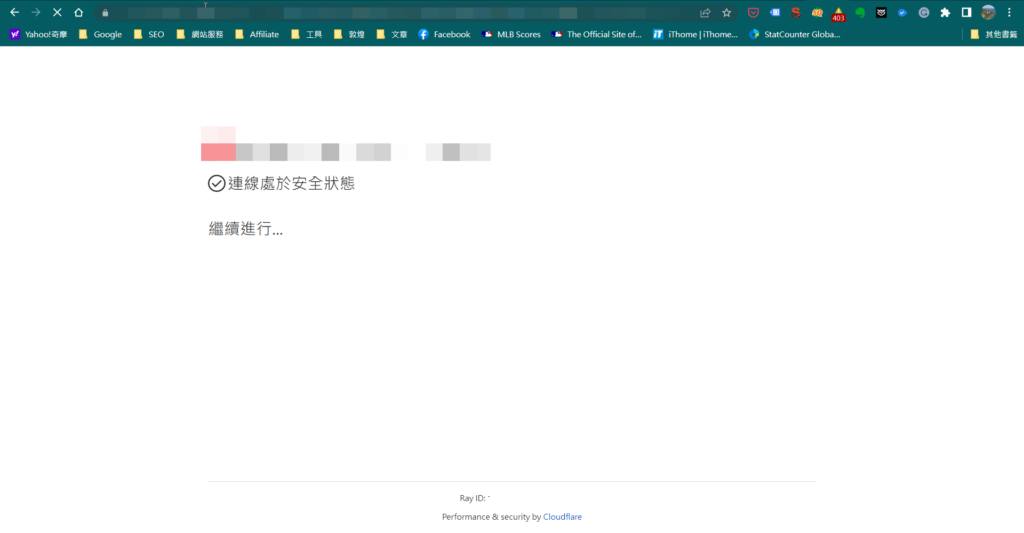
這是指主機端的防火牆設定太嚴格、拒絕Screaming Frog的請求,自然就無法爬取了,這通常會反應在回應代碼是"403",這時候變更User-Agent也沒用,主機就是不給爬取。更有甚者,可能我們要瀏覽網頁時被要求先證明是"真人",對我來說這根本就是矯枉過正,連爬都不想爬了,技術上確實也很難處理這種問題。
撇除SEO,使用者體驗也很糟糕,網站如果那麼不想讓人看,乾脆不要做!話說回來,在使用任何主機或資安服務時都要留意這個問題,以下的截圖就是使用Cloudflare的網站,但這不是Cloudflare的問題,是網管沒有正確設定!
Screaming Frog版本
這是一個小提醒,請盡量使用最新版的Screaming Frog,雖然我沒遇過版本問題造成無法爬取,但只要是軟體就會有bug,難保它不會造成我們爬取的障礙,再說…Screaming Frog是蠻勤勞的優化跟推出新功能,用最新版本總是不吃虧的!
總結
Screaming Frog是SEO從業人員必備的工具,但不是每次都可以順利的爬取網站,我就被問過蠻多次的,問題點不外乎上面這幾點。通常Screaming Frog無法順利爬取內容就代表了Google也很可能遇到問題,務必要確認原因才行。
另一種狀況是網址過多、無法完整爬取,這時候也不用強求一定得爬完,說不定根據現有資料就有做不完的調整了!想知道更多Screaming Frog的運用可參考下列文章:
