
在前一篇文章說明過如何設定Screaming Frog排程、定期將資料匯至Google Drive之後,這篇文章會說明如何以這些資料來製作Looker Studio報表(前身為Data Studio)、監控網站狀態。進入正題前,先簡單介紹Looker Studio,Google推出的免費視覺化報表工具。
Looker Studio簡介:
Looker Studio是Google於2016年推出的免費視覺化報表服務(2022年由Data Studio更名為Looker Studio),簡而言之,使用者可以使用Looker Studio獲取各種服務的數據,再以這些數據搭配Looker Studio的視覺化報表製作功能,產出一目了然的視覺化報表。除了報表功能強大,還能彙整來自四面八方的資料於一份報表中,非常方便。
Looker Studio這個服務本身是免費的,Google也提供獲取Google Analytics、Google Search Console、Google Ads等等資料的免費連結器(connector),但如果想取得Facebook廣告、Google My Business等資料,就需要購買付費的連結器才能取用資料。
看到這邊應該會有一個疑問:什麼是連結器?簡而言之,它是一個中介服務,Looker Studio本身沒有儲存我們使用服務的資料,必須要透過連結器跟Google Analytics、Google Search Console、Google Ads等服務取用資料才能製作報表,就姑且想成…Looker Studio跟資料源間的橋梁吧!
如果想更理解Looker Studio請參考這篇文章,本文會把重點放在跟Screaming Frog相關的功能、報表。
Looker Studio資料取用:
在上一篇文章已經說明如何將Screaming Frog的爬取結果匯至Google Drive,這些結果是以Google Sheets保存在Google Drive中,而Looker Studio提供了Google試算表的連結器,我們便是要以Google試算表的連結器取用保存於Google Drive中的Screaming Frog相關Google Sheets來製作報表。
通常我們保存於Google Drive的試算表有不少檔案,我建議直接於Looker Studio的介面中輸入想用來製作報表的Google Sheets網址,不要用瀏覽的方式,那真是曠日廢時。Screaming Frog爬取的資料很多,以下只說明如何以「Internal:HTML」、「External:HTML」、「Custom Crawl Overview」來製作Looker Studio報表。
Looker Studio報表製作:
Internal:HTML:
這檔案是Screaming Frog最重要的輸出資料,可以看到所有內部HTML(就是所有內部網頁,不含圖片、CSS等等)的可索引性、主機回應代碼、標準網址、網頁標題與Meta描述等等,如有串接Google Search Console,也會看到相關資料。
這張報表在Google Sheet的檔名是「internal_html」,成功取用資料後便可用來製作很多報表,例如索引監控、網頁回應碼監控等等,如果有串接Google Search Console,這邊也會顯示爬取資料。
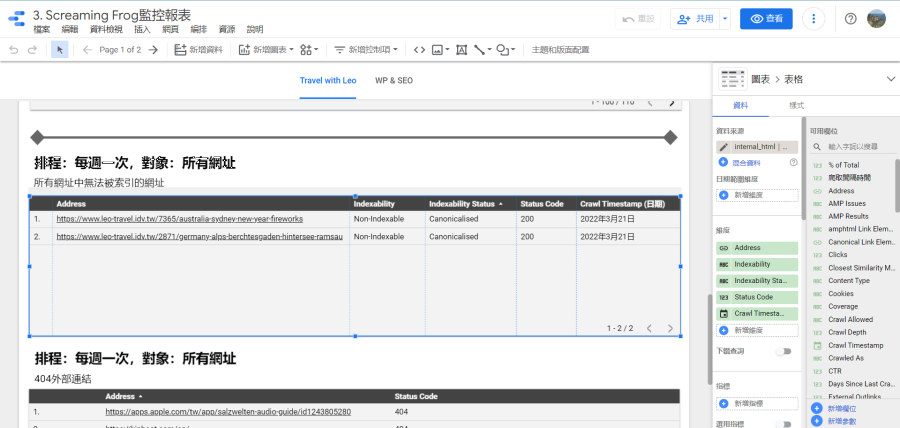
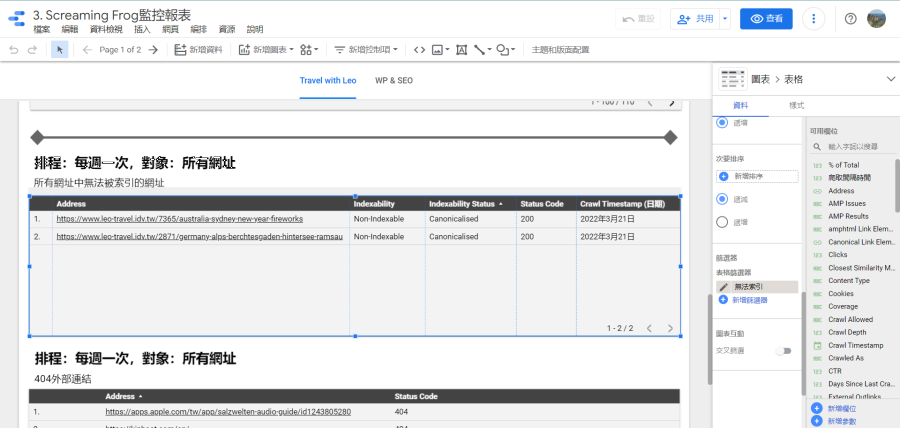
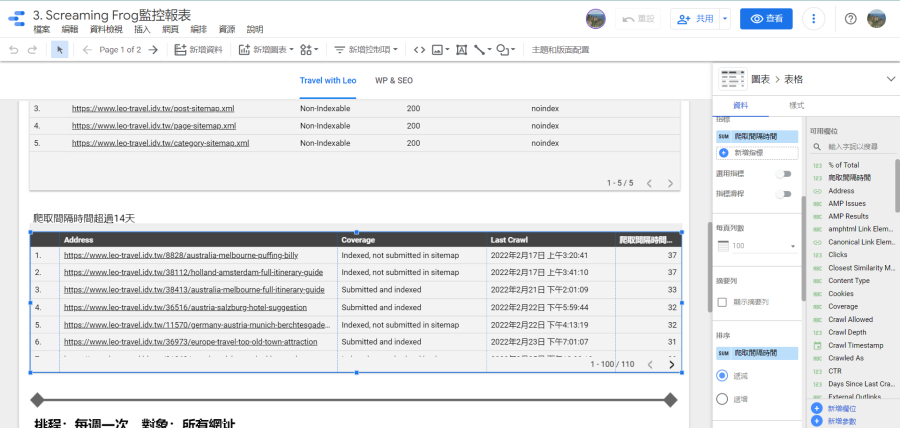
找出無法被索引的網址:
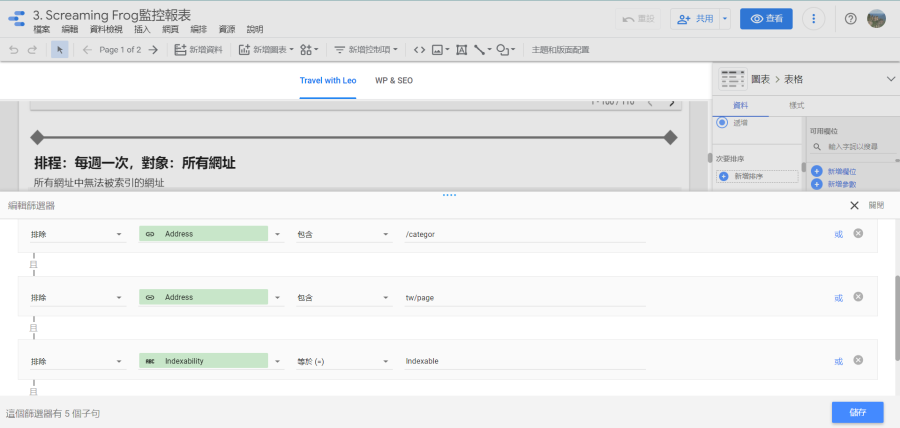
在製作Looker Studio報表時前要先規劃想監控哪些異常數據或資訊,以我來說…只需要監控哪些網址無法被索引(noindex、301轉址、網頁不存在等等),所以就會使用「internal_html」搭配Looker Studio的篩選器,找出「可能」有問題的網頁。以下圖為例,我是要找出「Indexability」不是「Indexable」的網頁(即排除「Indexability」等於「Indexable」),看看這些網頁是否可以索引、為何不能索引、伺服器回應的代碼是什麼。
通常一個網站會有許多網頁,但不是每一個網頁都需要進行SEO,以WordPress部落格來說,SEO的主力頁面是部落格文章,只要監控這些頁面即可,以負面表列的方式來篩選便是排除網址含tag、category的頁面。
監控Google Search Console的索引狀態:
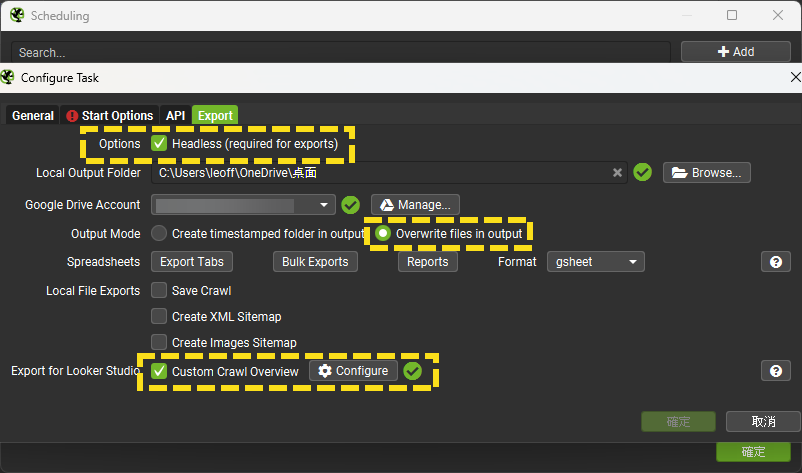
Google在2022年1月底釋出Google Search Console的網址檢查工具API後(相關連結),Screaming Frog便火速整合到它的服務中(官方說明),讓使用者可以一次取得大量的網址檢查工具結果、不用再一一查詢(但還是有使用量限制,請參考前面的相關連結)。如果要於排程工具使用這個API,在儲存排程設定檔時需勾選前述Screaming Frog官方說明中的「Enable URL Inspection」,並於排程設定畫面勾選使用Google Search Console API,兩者皆須完成!
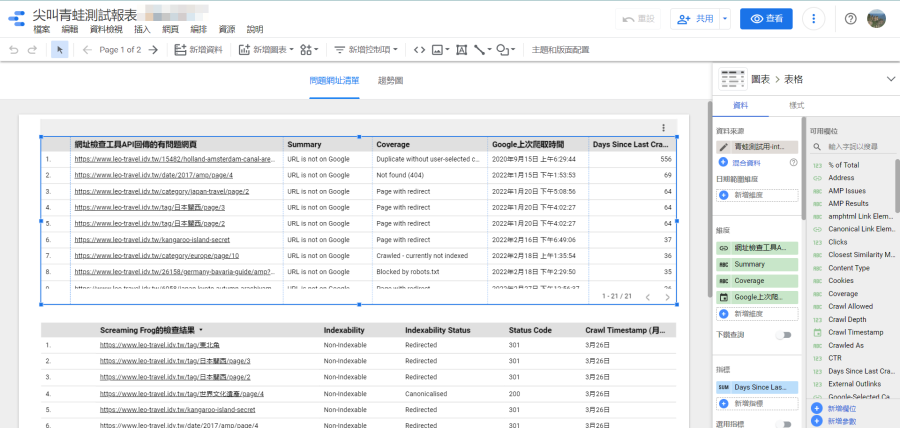
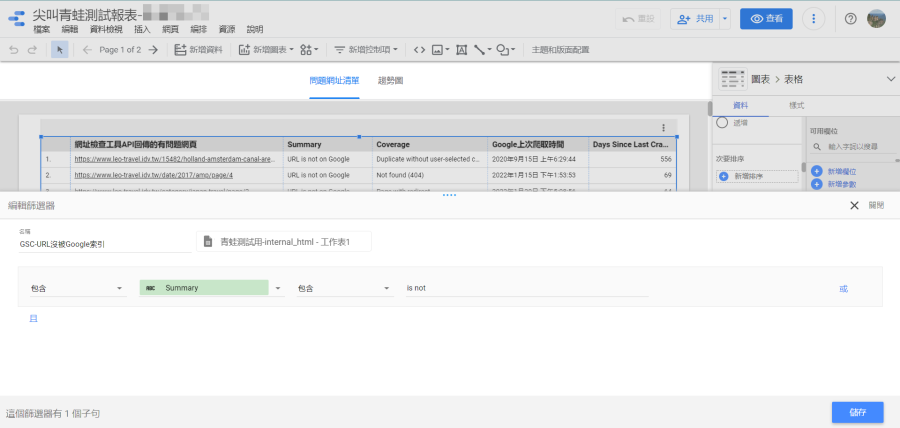
如果有順利取得Google Search Console的網址檢查工具資料,可於「internal_html」看到「Summary」、「Coverage」、「Last Crawl」、「Days Since Last Crawled」等資料。這邊的重點當然就是找出沒被Google索引的頁面(Summary包含is not),然後根據「Coverage」(即「涵蓋範圍」)來確認問題點。
另一個很有趣的資料是「Days Since Last Crawled」,即Google上次爬取是幾天前,這數據沒有絕對的好壞…如果很頻繁更新資料但Google卻經常2-3周才爬取一次,這就很有問題;反之,如果網站2-3個月才偶爾更新,那即使Google一個月爬取一次也不用太擔心。總之…這數據的解讀要搭配網站實際運作的狀況,以我來說,是會挑出上次爬取時間超過兩周的頁面,看看是否有問題。
Custom Crawl Overview:
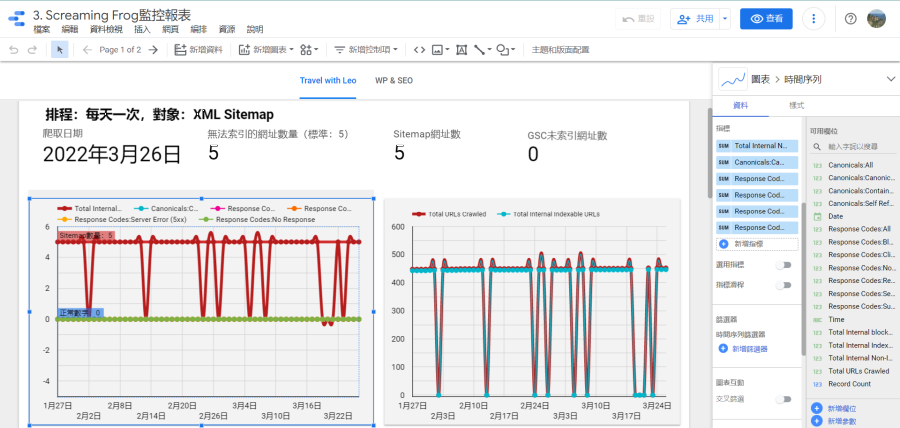
這報表的用途是建立索引統計狀態的趨勢圖,根據例外管理原則,我是用這個資料源來觀察XML Sitemap無法索引的網址,正常的數據是「0」,即XML Sitemap不該存在這種網址。即使在WordPress這種對SEO非常友善的系統,還是很容易發生這種狀況,例如:網址被以301轉址轉到其他頁面卻沒下架、購物車網頁被設定noindex卻沒由XML Sitemap排除。
這個報表對應的Google Sheets檔案其檔名結尾為「custom_summary_report」,需要於Screaming Frog的排程設定仔細調整才能於Google Sheets產出檔案,詳情請參考這一篇文章。
正確的產出Custom Crawl Overview的Google Sheets之後,便可用它來製作索引異常網址數量趨勢圖,索引異常包含「Response Codes:Blocked by Robots.txt」「Response Codes:Redirection (3xx)」「Response Codes:Client Error (4xx)」「Canonicals:Canonicalised」等等。
如果排程爬取的對象是XML Sitemap檔案,則這些檔案也會納入爬取的網址,以我為例…我是爬取XML Sitemap的索引檔、總共有五個XML Sitemap檔案,這些檔案都是noindex,所以…無法被索引的連結數就只能是5,超過就有問題!
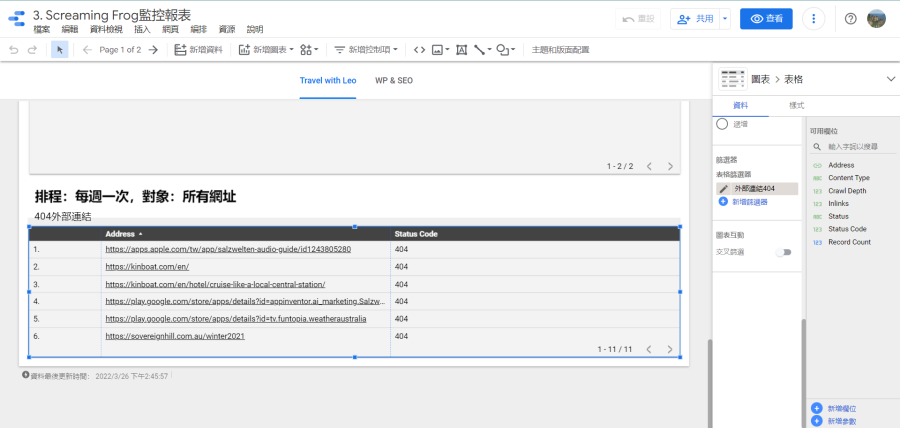
External:HTML:
這邊可以看到所有Screaming Frog爬取的外部HTML的資料,在Google Sheets的檔名是「external_html」,我是用來檢查是否存在失效的外部連結(Sttus Code等於404)。相較於上面的報表,這重要性低多了,但我的網站有置放大量外部連結,需監控失效外部連結的狀態,以免影響使用者體驗。找到之後可開啟Screaming Frog的爬取結果,找出置放這些連結的網址並修正。
要注意的是…找到這些連結後還要自己再測試一次,有時候會誤判,如果被認定為404但我可以正常連線,我就會忽略它!
心得:
Screaming Frog的排程搭配Looker Studio便可以產出監控報表,提早察覺網站的問題並快速修正。以我重視的索引監控為例,Google Search Console顯示的已經是結果,當那邊的結果不如預期問題可能存在很久了,因為還有時間差,善加利用Screaming Frog便可快速調整!除了監控索引相關設定與狀態,當然也可用來監控圖檔大小、文案設定等等,就看自己需求應變吧!
話說回來,不管是排程或者Looker Studio報表都算是進階功能,建議先熟悉基本設定與報表,並具備基本的SEO知識,才能好好使用,所以…建議先好好閱讀下列文章來了解Screaming Frog可以做什麼。
