
Screaming Frog是非常知名的SEO檢測工具,除了強大的爬取功能,還可以設定排程來定期檢測網站狀態,更重要的是…可以產出Looker Studio所需要的資料源、建立視覺化報表。這篇文章將會介紹如何以付費版的Screaming Frog建立排程以及將資料輸出到Google Drive的方式,至於如何使用Google Drive資料來製作Looker Studio報表請看這一篇文章。文章目錄:
Screaming Frog排程目的
設定Screaming Frog排程這件事不是重點,核心是:我們想監控什麼問題?排程的目的是為了產出足以監控並修正這些問題的資料。我的網站是以WordPress製作、目的:設定Screaming Frog排程來自動產出「建立監控索引狀態的Looker Studio報表」所需要的資料源。監控標的:
- XML Sitemap網址的索引狀態:
- 排程頻率:每天一次
- XML Sitemap上的網址是網站最重要的網址,需要經常確認這些網址是否有索引問題
- 我是使用Yoast SEO,所以網站有Sitemap的Index檔案,可以將這個檔案設定為爬取網址資料源
- 這個排程只爬取XML Sitemap上的網址、不會花太久時間,再加上這些網址很重要,所以設定為每天爬取
- 文章、分類、標籤、頁面的索引狀態:
- 排程頻率:每週一次
- 這幾個模組是WordPress部落格網站的重要內容,若你有用WooCommerce建議監控產品相關模組
- 這個排程會抓比較多網址,再加上我很重視網站的索引問題,所以出問題的機率不高(還是會出錯就是了),排程頻率設定為每週一次
為了完成上述兩大目的,我設定了兩個排程,排程頻率、爬取的網址與輸出的內容都有差異。如果你是想利用Screaming Frog監控其他問題,或者網站不是以WordPress架站,還是可以參考本文大多數內容,只是需要輸出的資料以及Looker Studio的報表設計方向會有差異,排程設定的邏輯是大同小異的。
接下來,就來看看如何使用Screaming Frog的排程產出Looker Studio的資料源吧,雖然我有兩大目的,但不會分開講解、只會說明設定方式與重點事項,看完之後再依自己的需求調整吧!
Screaming Frog排程設定
開啟Screaming Frog後,由主選單最左邊的「File」點擊「Scheduling」便可以進入Screaming Frog的排程清單介面,再點擊「Add」便可以新增排程。進入設定前特別提醒一點:
電腦需開機且接上電源才能觸發排程(不用開啟Screaming Frog),我一開始在筆電設好排程但是常常沒觸發,才發現電腦接上電源線是啟動排程的必要條件,一開始還以為…我哪邊用錯了!
進到新增排程的畫面後有三個頁籤:General、Start Options、API、Export,分別有重要設定,一定要仔細處理才不會出現錯誤。
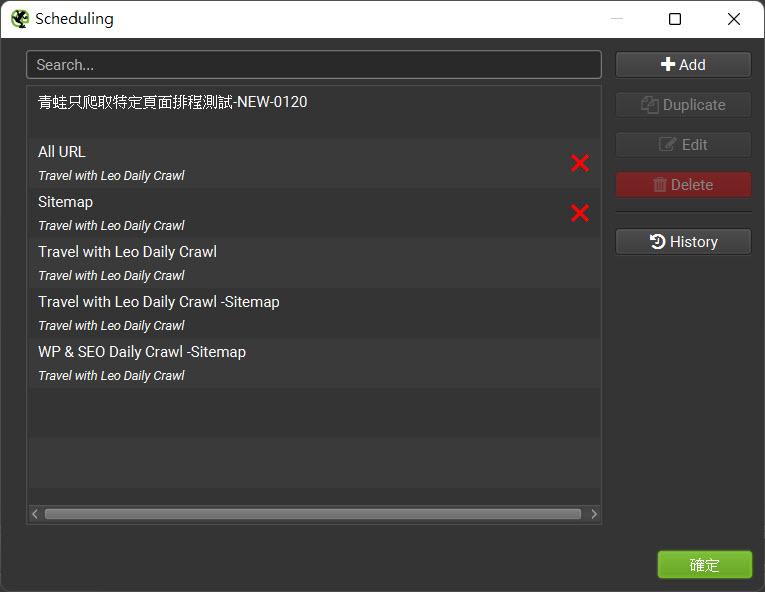
General
- 名稱設定:有兩個欄位,除了會顯示在排程清單,也會影響到Google Drive的資料夾命名方式,要謹慎設定
- Task Name:通常是用來描述排程性質,例如每週爬取、每日爬取等等,或者是爬取的內容(整站爬取或只爬取XML Sitemap)
- Project Name:通常是用來描述爬取對象,例如網站名稱(Travel with Leo、WP & SEO)
- Date/Time:設定何時開始爬取,以及爬取頻率(每日、每週、每月,或只進行一次)
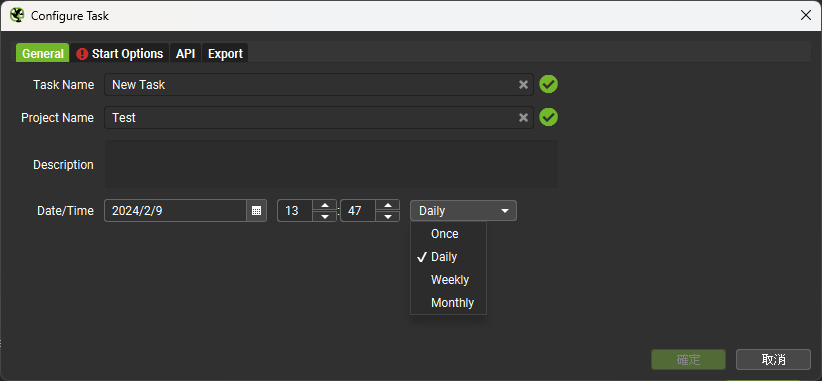
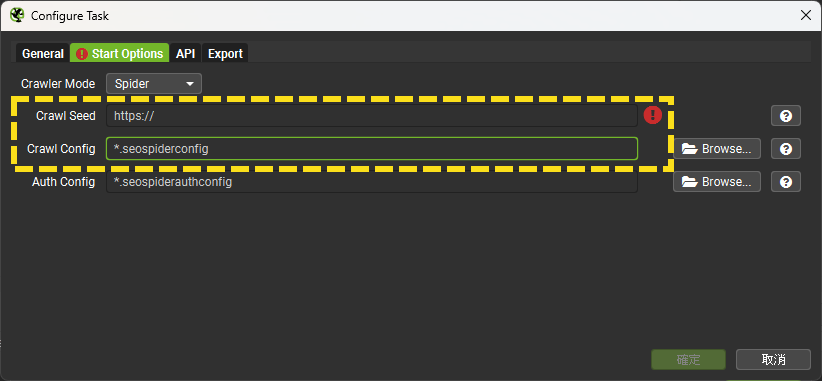
Start Options
這邊有三個重要設定,其中一個出錯就會無法觸發排程!
- Crawler Mode:
- Spider:於「Crawl Seed」輸入要爬取的網域
- List:於「Crawl Seed」上傳網址清單
- 需要是CSV檔或XML Sitemap檔案,請點擊「Browse」指定網址清單位置
- 如果要爬取XML Sitemap,建議上傳Index檔
- 以本站來說,是https://www.wpandseo.tw/sitemap_index.xml
- 進到網址後按右鍵點擊「另存新檔」便可下載檔案,再於「Crawl Seed」指定要爬取這個檔案
- Crawl Config:跟Screaming Frog說明根據哪個爬取設定檔來爬取網站內容,請點擊「Browse」指定設定檔位置,不知道如何產出設定檔請參考這一篇文章
- 請勿隨意變更Crawl Config跟Crawl Seed於電腦資料夾/檔案總管的位置,如變更檔案位置務必要於這邊重新指定,不然無法觸發排程
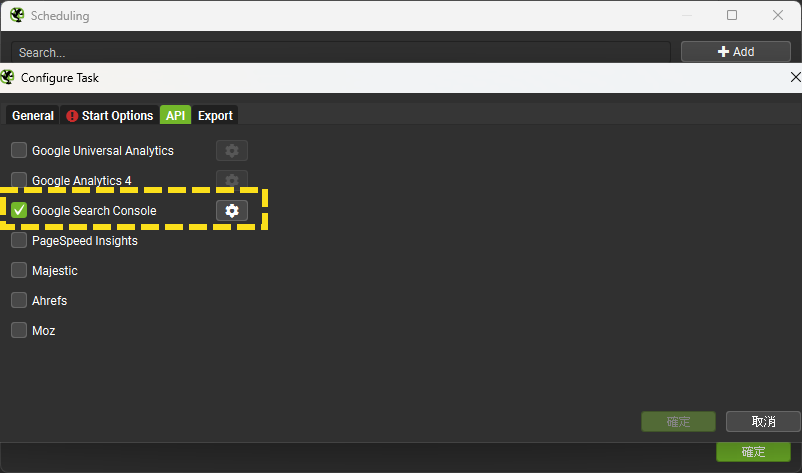
API
Screaming Frog有整合GA 4、GSC等等工具的API,如果想在排程執行的時候也利用這些API取得資料,就要在API頁籤勾選你要用的。這只是跟系統說你要用哪些API,要如何使用需另外設定並存到爬取設定檔(參考說明)。
Export
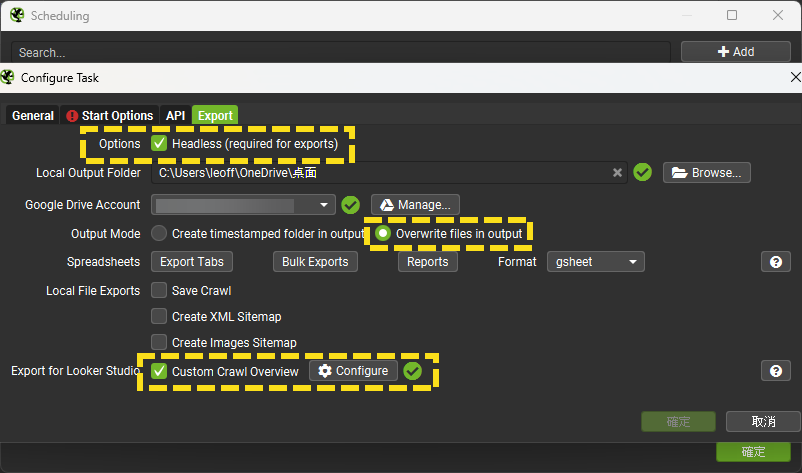
這是跟Screaming Frog說明如何匯出檔案,非常繁瑣,我會先說明設定細節再以截圖分享我的設定方式。
- 請勾選「Headless」,這是匯出報表的必要選項
- Local Output Folder:
- 爬取結果檔案(副檔名:seospider)的存放位置,可用Screaming Frog開啟這檔案詳細檢視爬取內容
- 建議為每個排程設定獨立的資料夾,原因等等說明
- Google Drive Account:
- 如果設計Screaming Frog的Looker Studio報表,需要先將爬取內容以gsheet的格式輸出到Google Drive,再用這些gsheet設定報表
- 建議輸入你用來製作Looker Studio報表的Google帳號
- 沒將爬取內容輸出到Google Drive就無法製作自動更新的Looker Studio報表!
- Output Mode:請選取Overwrite files in output
- Overwrite files in output:輸出的檔案會新蓋舊,只留存一份檔案、無歷史資料
- Create timestamped folder in output:每次爬取都會於Google Drive以建立一個以爬取時間命名的資料夾
- 因為我是要輸出Screaming Frog的爬取內容來製作自動更新的Looker Studio報表,需要確保資料源會自動更新,故選擇「Overwrite files in output」;如選擇「Create timestamped folder in output」會導致最新爬取內容的位置不斷變動,這樣無法製作自動更新的報表
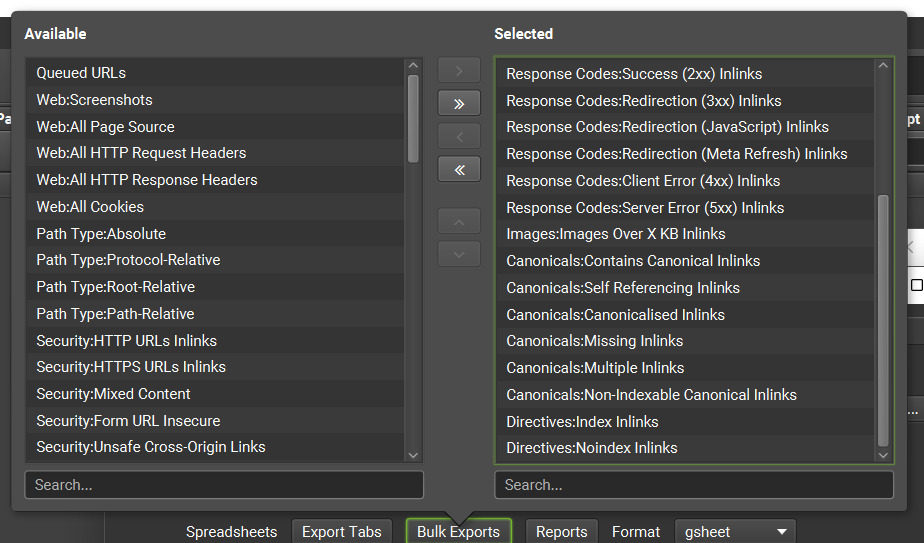
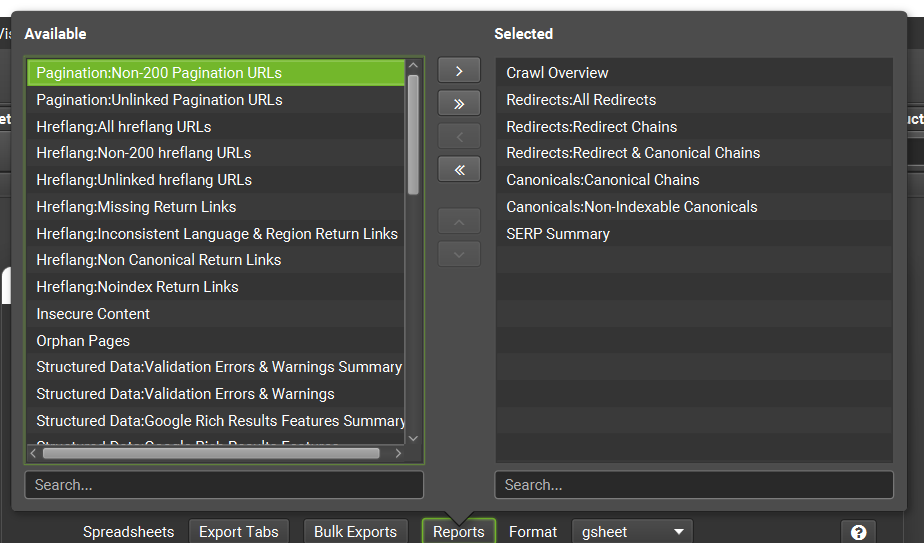
- Spreadsheets:
- 可選擇輸出哪些Export Tabs、Bulk Exports、Reports
- 如果不熟悉Screaming Frog的輸出內容,可以全部輸出再於Google Drive中一一檢視
- 輸入越多報表排程會跑越久,建議熟悉後調整輸出的內容
- Format:可輸出CSV、XML、XLSX、gsheet等等,如要用來製作Looker Studio報表請選擇gsheet
- 可選擇輸出哪些Export Tabs、Bulk Exports、Reports
- Local File Exports:選擇要於本機(不是Google Drive)儲存哪些爬取資料,勾選「Save Crawl」即可
- 如前所述,輸出檔案的副檔名是seospider,且…無法自訂檔名,每個爬取排程輸出的檔名都一樣
- 如果設定多個排程且輸出到同一個資料夾,因輸出的檔名都一樣,可能會產生後蓋前的問題
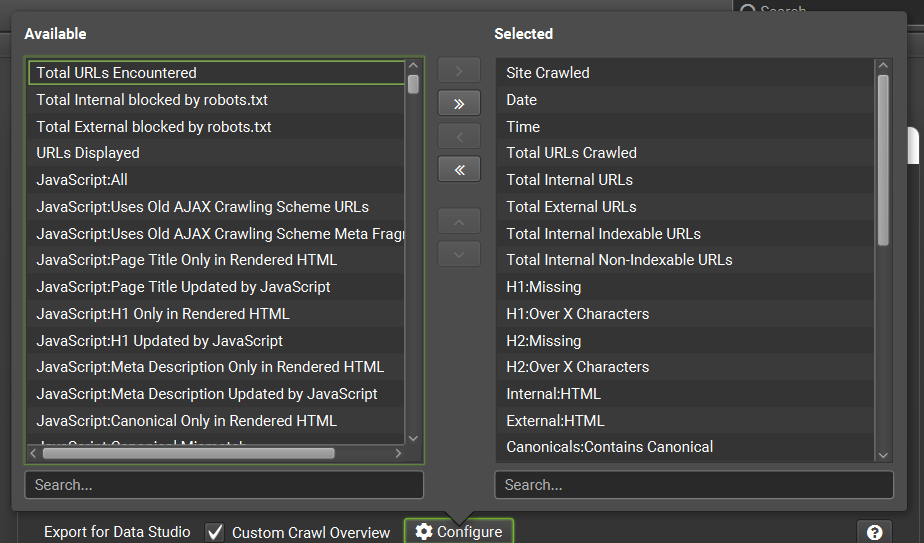
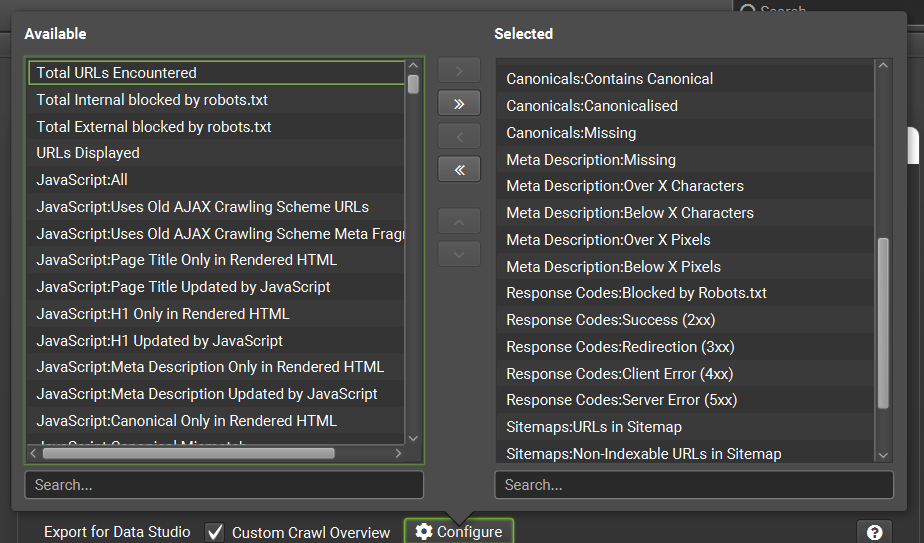
- Export for Looker Studio:
- 請勾選「Custom Crawl Overview」,這樣才能建立統計報表用的資料源
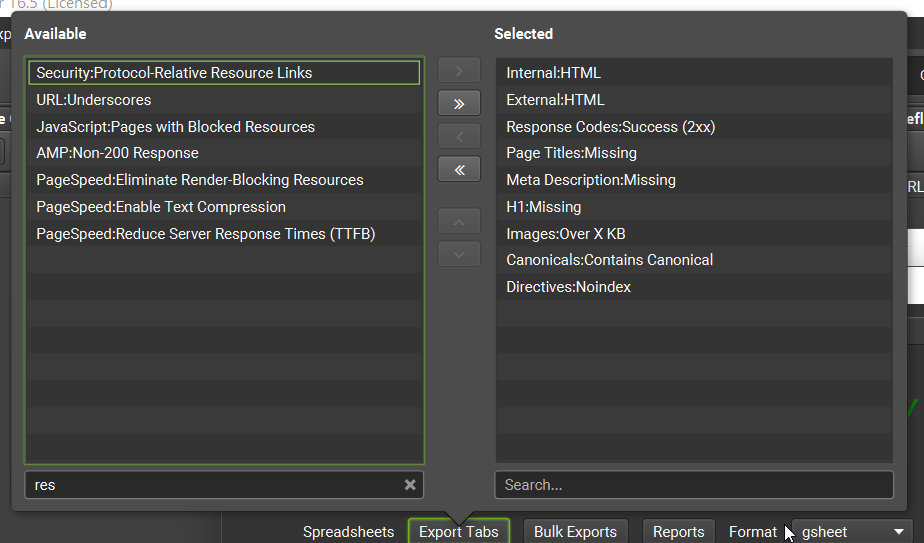
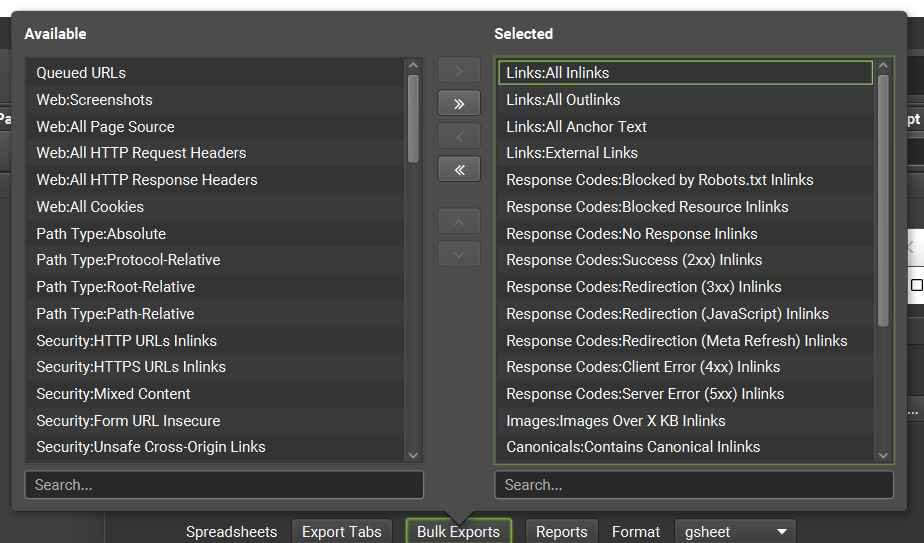
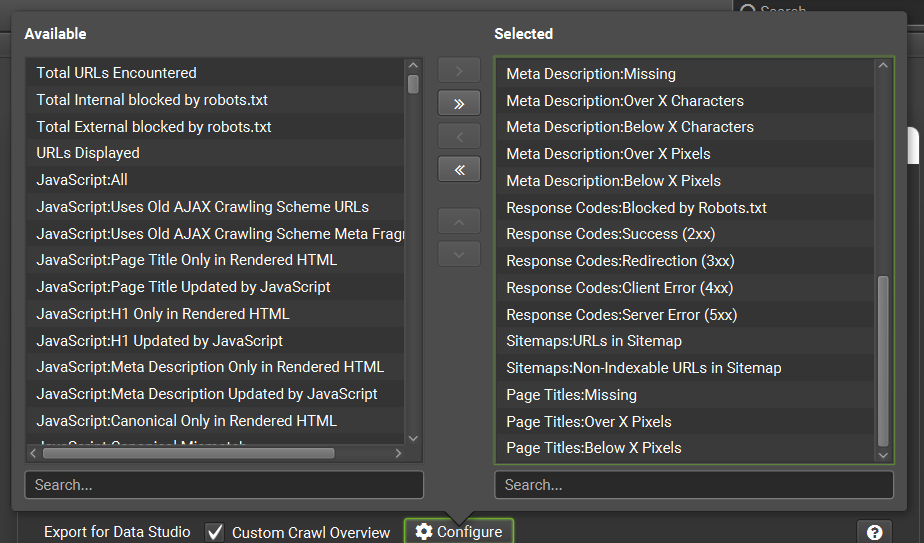
- 請於「Configure」選擇要輸出的欄位,這是必填,沒選欄位就無法建立排程
- 一定要選擇「Date」,這樣才有日期欄位來建立趨勢圖
- 可能用的到的資料都要選,不確定的話就…全選
- 如果沒選擇要輸出哪些欄位,「Custom Crawl Overview」的報表就沒內容
- 選擇好要輸出的欄位後就不要再調整欄位,以免導致欄位大亂、影響到Looker Studio報表
設定畫面截圖
輸出內容設定截圖
重點輸出報表
Screaming Frog可輸出的報表非常之多,讓人眼花撩亂,若輸出所有資料除了會拉長排程處理時間,也會導致Google Drive儲存太多無用資料,耗費太多時間找出真正要用的資料源,初期建議匯出下列三個報表,再搭配彙整報表,即足夠製作Looker Studio報表:
- Export Tabs:
- Internal:HTML:最重要的輸出資料,可以看到所有內部HTML(就是所有內部網頁,不含圖片、CSS等等)的可索引性、主機回應代碼、標準網址、網頁標題與Meta描述等等,如有串接Google Search Console,也會看到相關資料
- External:HTML:可以看到所有外部HTML的資料,用來檢查是否存在失效的外部連結
- Reports:
- Redirects:Redirect Chains:顧名思義,就是看看是否存在轉址迴圈(A轉到B、B又轉到A),若有的話須修正,不然使用者無法連到網頁
小結
Screaming Frog的排程設定頗複雜、需要不斷嘗試才能找出最佳設定,不過可以很輕易的複製排程,就是第一次比較累。以上的建議設定方式是為了產出監控索引狀態的Looker Studio自動更新報表所需要的資料源,若你想產出其他用途的報表就不一定適用。
老話一句:初期先多方嘗試輸出資料的方式來實驗可以做出的報表類型,確認無誤後就盡量不要再調整Screaming Frog的排程設定與必要檔案的位置!進到下一階段前再提示一下重點:
- 電腦需要開機且接上電源才能觸發排程,但不用開啟Screaming Frog
- 需謹慎命名Project Name跟Task Name,這關乎Google Drive的資料夾路徑,千萬別隨意變更
- 選定爬取設定檔跟爬取網址檔案後就不要隨意變更位置,以免系統抓不到資料導致無法觸發排程
- 要謹慎設定輸出到Google Drive的檔案內容
- 排程清單出現紅色X一定要進去檢查,這代表排程有錯、無法觸發
Screaming Frog排程輸出資料檢查
前面有提到Screaming Frog的輸出資料存放位置,排程跑完之後請到那個資料夾確認輸出內容。如前所述,如果不確定要輸出哪些內容就選擇輸出全部內容,再逐一檢視資料表內容判斷哪些是必要的、調整輸出內容。
輸出資料的檢查需搭配報表分析目的且要對SEO有一定的熟悉程度,說到底…最難的其實是要理解輸出資料的內容與解讀方式,後續才能設定Looker Studio報表,建立排程只是繁瑣。
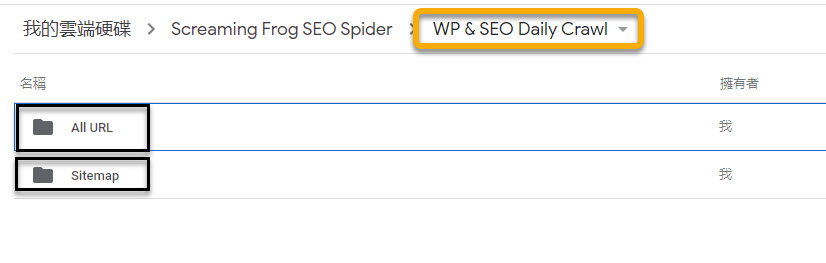
順帶一提,Screaming Frog在Google Drive最上層的資料夾名稱是「Screaming Frog SEO Spider」,請勿由Google Drive變更任何Screaming Frog相關的資料夾或檔案名稱,以免造成Screaming Frog誤判資料不存在而建立新的資料夾或檔案。
心得
Screaming Frog的排程是非常強大的工具,再搭配Looker Studio報表便可以產出監控報表,提早察覺網站的問題並快速修正。以我重視的索引監控為例,Google Search Console顯示的已經是結果,當那邊的結果不如預期問題可能存在很久了,因為還有時間差,善加利用Screaming Frog便可快速調整!
話說回來,不管是排程或者Looker Studio報表都算是進階功能,建議先熟悉基本設定與報表,並具備基本的SEO知識,才能好好使用,所以…建議先好好閱讀下列文章來了解Screaming Frog可以做什麼。
延伸閱讀
- SEO小教室|Google Search Console簡介、基本功能說明、成效與索引報告使用建議
- SEO小教室|網站地圖Sitemap用途說明、產出與提交方式、特殊網址處理心得
- SEO小教室|數據分析神器-Looker Studio視覺化報表核心功能與用途分享
- SEO小教室|流量下滑分析-步驟一:以「指標」、「管道」、「時間段」釐清問題
- SEO小教室|電商網站常見重複性內容問題與建議處理方式
- SEO小教室|如何用標準網址Canonical Tag處理重複性內容、與301轉址的差異
- SEO小教室|301轉址懶人包-轉址簡介、開發注意事項、評估方式、替代方案
- SEO小教室|SEO成效評估重點指標與推薦工具分享
- WordPress|內容網站SEO – 網域與索引、重點功能、內容編輯等七大主題教學
- WordPress|必裝SEO外掛 – 超完整Yoast SEO設定教學
- SEO小教室|排名追蹤工具SE Ranking介紹:專案設定、關鍵字排名報表、篩選功能
- SEO小教室|2021年SEO元素週期表-內容、架構、HTML
- SEO小教室|Rand Fishkin(蘭德.費希金)2019年SEO排名要素研究報告讀後心得
